8.用于爬虫
很多人问这个框架能不能爬虫?
答:此框架不仅可以对标celery框架,也可以取代scrapy框架。
无论是比 自由度、兼容常规代码程度、用户需要编写的实际代码行数、消息万无一失可靠度、对爬虫的qps频率/并发控制手段、超高速调度请求, 此框架从以上任何方面远远超过scrapy,一切都是只会是有过之而无不及。
应该还是主要是很浮躁,不仅没看详细文档,应该是连简介都没看。 分布式函数调度框架,定位于调度用户的任何函数,只要用户在函数里面写爬虫代码,就可以分布式调度爬虫,并且对爬虫函数施加20种控制功能, 例如 qps恒定 任何时候随意关机重启代码消息万无一失确认消费 非常简单的开启多进程叠加线程/协程,这些强大的功能绝大部分爬虫框架还做不到。 此框架如果用于爬虫,不管从任何方面比较可以领先scrapy20年,也比任意写的爬虫框架领先10年。 不是框架作者代码编写实力问题,主要是思维问题,爬虫框架一般就设计为url请求调度框架,url怎么请求都是被框内置架束缚死了, 所以有些奇葩独特的想法在那种框架里面难以实现,需要非常之精通框架本身然后改造框架才能达到随心所欲的驾驭的目的。 而此框架是函数调度框架,函数里面可以实现一切任意自由想法,天生不会有任何束缚。 主要还是思想问题,国内一般人设计的爬虫框架都是仿scrapy api,天生不自由受束缚。
此框架如果用于写爬虫,建议的写法是一种页面(或者接口)对应一个函数,例如列表页是一个函数,详情页是一个函数。 1个函数里面只包括一次请求(也可以两三次请求,但不要在函数本身里面去for循环遍历发十几个请求这种写法),
8.1 演示获取汽车之家资讯的 新闻 导购 和 评测 3个板块 的 文章。
页面连接 https://www.autohome.com.cn/all/
这是一个非常经典的列表页-详情页两层级爬虫调度。演示爬虫一定最少需要演示两个层级的调度,只要会了两层级爬虫,3层级就很简单。
此框架如果用于写爬虫,建议的写法是一种页面(或者接口)对应一个函数,例如列表页是一个函数,详情页是一个函数。
1个函数里面只包括一次请求(也可以两三次请求,但不要在函数本身里面去for循环遍历发十几个请求这种写法),
"""
演示分布式函数调度框架来驱动爬虫函数,使用此框架可以达使爬虫任务 自动调度、 分布式运行、确认消费万无一失、超高速自动并发、精确控频、
种子过滤(函数入参过滤实现的)、自动重试、定时爬取。可谓实现了一个爬虫框架应有的所有功能。
此框架是自动调度一个函数,而不是自动调度一个url请求,一般框架是yield Requet(),所以不兼容用户自己手写requests urllib的请求,
如果用户对请求有特殊的定制,要么就需要手写中间件添加到框架的钩子,复杂的需要高度自定义的特殊请求在这些框架中甚至无法实现,极端不自由。
此框架由于是调度一个函数,在函数里面写 请求 解析 入库,用户想怎么写就怎么写,极端自由,使用户编码思想放荡不羁但整体上有统一的调度。
还能直接复用用户的老函数,例如之前是裸写requests爬虫,没有规划成使用框架爬虫,那么只要在函数上面加一个@task_deco的装饰器就可以自动调度了。
而90%一般普通爬虫框架与用户手写requests 请求解析存储,在流程逻辑上是严重互斥的,要改造成使用这种框架改造会很大。
此框架如果用于爬虫和国内那些90%仿scrapy api的爬虫框架,在思想上完全不同,会使人眼界大开,思想之奔放与被scrapy api束缚死死的那种框架比起来有云泥之别。
因为国内的框架都是仿scrapy api,必须要继承框架的Spider基类,然后重写 def parse,然后在parse里面yield Request(url,callback=annother_parse),
请求逻辑实现被 Request 类束缚得死死的,没有方便自定义的空间,一般都是要写middware拦截http请求的各个流程,写一些逻辑,那种代码极端不自由,而且怎么写middware,
也是被框架束缚的死死的,很难学。分布式函数调度框架由于是自动调度函数而不是自动调度url请求,所以天生不存在这些问题。
用其他爬虫框架需要继承BaseSpider类,重写一大堆方法写一大堆中间件方法和配置文件,在很多个文件夹中来回切换写代码。
而用这个爬虫,只需要学习 @task_deco 一个装饰器就行,代码行数大幅度减少,随意重启代码任务万无一失,大幅度减少操心。
这个爬虫例子具有代表性,因为实现了演示从列表页到详情页的分布式自动调度。
"""
"""
除了以上解释的最重要的极端自由的自定义请求解析存储,比普通爬虫框架更强的方面还有:
2、此爬虫框架支持 redis_ack_able rabbitmq模式,在爬虫大规模并发请求中状态时候,能够支持随意重启代码,种子任务万无一失,
普通人做的reids.blpop,任务取出来正在消费,但是突然关闭代码再启动,瞬间丢失大量任务,这种框架那就是个伪断点接续。
3、此框架不仅能够支持恒定并发数量爬虫,也能支持恒定qps爬虫。例如规定1秒钟爬7个页面,一般人以为是开7个线程并发,这是大错特错,
服务端响应时间没说是永远都刚好精确1秒,只有能恒定qps运行的框架,才能保证每秒爬7个页面,恒定并发数量的框架差远了。
4、能支持 任务过滤有效期缓存,普通爬虫框架全部都只能支持永久过滤,例如一个页面可能每周都更新,那不能搞成永久都过滤任务。
因为此框架带有20多种控制功能,所以普通爬虫框架能实现的控制,这个全部都自带了。
"""
爬虫任务消费代码
代码在 https://github.com/ydf0509/distributed_framework/tree/master/test_frame/car_home_crawler_sample/test_frame/car_home_crawler_sample/car_home_consumer.py
import requests
from parsel import Selector
from function_scheduling_distributed_framework import task_deco, BrokerEnum, run_consumer_with_multi_process
@task_deco('car_home_list', broker_kind=BrokerEnum.REDIS_ACK_ABLE, max_retry_times=5, qps=10)
def crawl_list_page(news_type, page, do_page_turning=False):
""" 函数这里面的代码是用户想写什么就写什么,函数里面的代码和框架没有任何绑定关系
例如用户可以用 urllib3请求 用正则表达式解析,没有强迫你用requests请求和parsel包解析。
"""
url = f'https://www.autohome.com.cn/{news_type}/{page}/#liststart'
resp_text = requests.get(url).text
sel = Selector(resp_text)
for li in sel.css('ul.article > li'):
if len(li.extract()) > 100: # 有的是这样的去掉。 <li id="ad_tw_04" style="display: none;">
url_detail = 'https:' + li.xpath('./a/@href').extract_first()
title = li.xpath('./a/h3/text()').extract_first()
crawl_detail_page.push(url_detail, title=title, news_type=news_type) # 发布详情页任务
if do_page_turning:
last_page = int(sel.css('#channelPage > a:nth-child(12)::text').extract_first())
for p in range(2, last_page + 1):
crawl_list_page.push(news_type, p) # 列表页翻页。
@task_deco('car_home_detail', broker_kind=BrokerEnum.REDIS_ACK_ABLE, qps=50,
do_task_filtering=True, is_using_distributed_frequency_control=True)
def crawl_detail_page(url, title, news_type):
resp_text = requests.get(url).text
sel = Selector(resp_text)
author = sel.css('#articlewrap > div.article-info > div > a::text').extract_first() or
sel.css('#articlewrap > div.article-info > div::text').extract_first() or ''
author = author.replace("\n", "").strip()
print(f'保存数据 {news_type} {title} {author} {url} 到 数据库') # 用户自由发挥保存。
if __name__ == '__main__':
# crawl_list_page('news',1)
crawl_list_page.consume() # 启动列表页消费
crawl_detail_page.consume()
# 这样速度更猛,叠加多进程
crawl_detail_page.multi_process_consume(4)
爬虫任务发布代码
代码在 https://github.com/ydf0509/distributed_framework/blob/master/test_frame/car_home_crawler_sample/car_home_publisher.py
from function_scheduling_distributed_framework import fsdf_background_scheduler
from test_frame.car_home_crawler_sample.car_home_consumer import crawl_list_page, crawl_detail_page
crawl_list_page.clear() # 清空列表页
crawl_detail_page.clear() # 清空详情页
# # 推送列表页首页,同时设置翻页为True
crawl_list_page.push('news', 1, do_page_turning=True) # 新闻
crawl_list_page.push('advice', page=1, do_page_turning=True) # 导购
crawl_list_page.push(news_type='drive', page=1, do_page_turning=True) # 驾驶评测
# 定时任务,语法入参是apscheduler包相同。每隔120秒查询一次首页更新,这部分可以不要。
for news_typex in ['news', 'advice', 'drive']:
fsdf_background_scheduler.add_timing_publish_job(crawl_list_page, 'interval', seconds=120, kwargs={"news_type": news_typex, "page": 1, "do_page_turning": False})
fsdf_background_scheduler.start() # 启动首页查询有没有新的新闻的定时发布任务
从消费代码可以看出,代码就是常规思维的平铺直叙主线程思维写代码,写函数代码时候无需考虑和框架怎么结合,写完后加个@task_deco装饰器就行了。
因为这不是类似国内的仿scrapy框架必须要求你必须继承个什么类,强迫你重写什么方法,然后yield Request(your_url,callback=my_parse)
此框架爬虫既能实现你无拘无束使用任意包来请求url和解析网页,又能很方便的使用到自动超高并发 超高可靠性的万无一失断点续传。
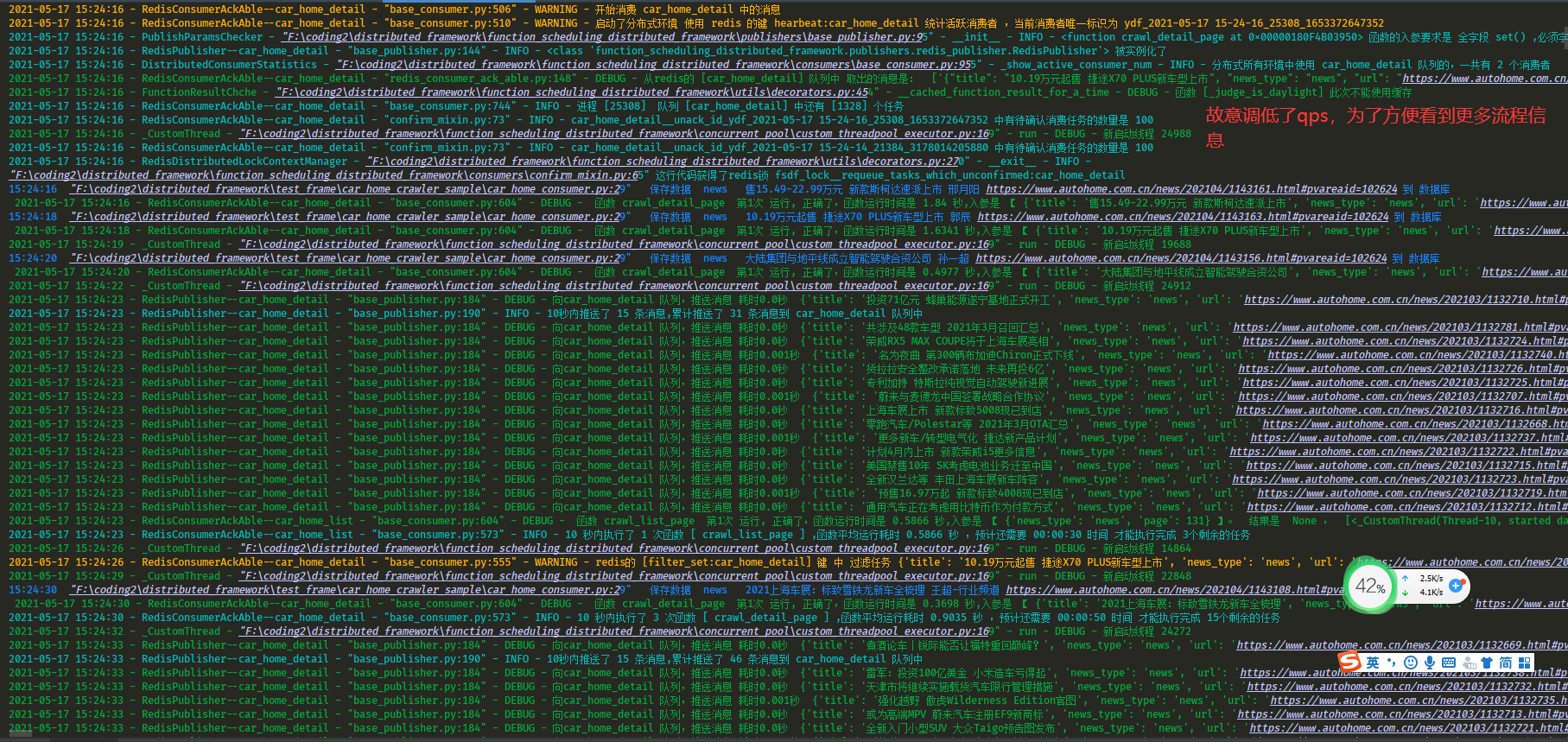
qps设置为很低时候,为了展示更多控制台日志流程细节,分布式函数调度框架驱动爬虫函数的慢速爬取运行截图。
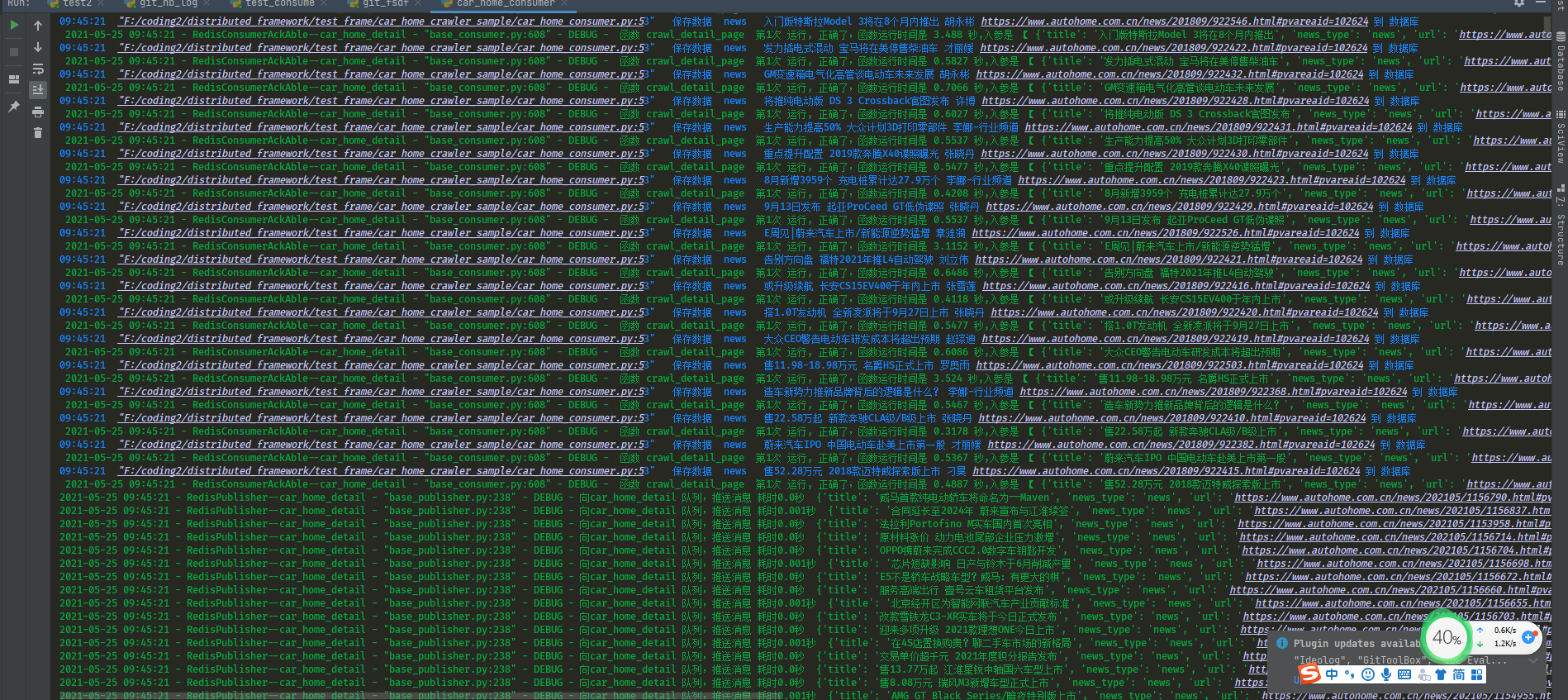
qps设置高时候的运行截图,分布式函数调度框架驱动爬虫函数的快速爬取运行截图。
8.2 演示经典的豆瓣top250电影的爬虫
页面连接 https://movie.douban.com/top250
这是一个非常经典的列表页-详情页两层级爬虫调度。演示爬虫一定最少需要演示两个层级的调度,只要会了两层级爬虫,3层级就很简单。
此框架如果用于写爬虫,建议的写法是一种页面(或者接口)对应一个函数,例如列表页是一个函数,详情页是一个函数。
1个函数里面只包括一次请求(也可以两三次请求,但不要在函数本身里面去for循环遍历发十几个请求这种写法),
from function_scheduling_distributed_framework import task_deco, BrokerEnum
import requests
from parsel import Selector
HEADERS = {'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0)', }
@task_deco('douban_list_page_task_queue', broker_kind=BrokerEnum.PERSISTQUEUE, qps=0.1) # qps 自由调节精确每秒爬多少次,远强于一般框架只能指定固定的并发线程数量。
def craw_list_page(page):
""" 函数这里面的代码是用户想写什么就写什么,函数里面的代码和框架没有任何绑定关系,框架只对函数负责,不对请求负责。
例如用户可以用 urllib3请求 用正则表达式解析,没有强迫你用requests请求和parsel包解析。
"""
""" 豆瓣列表页,获取列表页电影链接"""
url = f'https://movie.douban.com/top250?start={page * 25}&filter='
resp = requests.get(url, headers=HEADERS)
sel = Selector(resp.text)
for li_item in sel.xpath('//*[@id="content"]/div/div[1]/ol/li'):
movie_name = li_item.xpath('./div/div[2]/div[1]/a/span[1]/text()').extract_first()
movei_detail_url = li_item.xpath('./div/div[2]/div[1]/a/@href').extract_first()
craw_detail_page.push(movei_detail_url, movie_name)
@task_deco('douban_detail_page_task_queue', broker_kind=BrokerEnum.PERSISTQUEUE, qps=4)
def craw_detail_page(detail_url, movie_name):
"""豆瓣详情页,获取电影的详细剧情描述。"""
resp = requests.get(detail_url, headers=HEADERS)
sel = Selector(resp.text)
description = sel.xpath('//*[@id="link-report"]/span[1]/text()[1]').extract_first().strip()
print('保存到数据库:', movie_name, detail_url, description)
if __name__ == '__main__':
# craw_list_page(0)
# craw_detail_page('https://movie.douban.com/subject/6786002/','触不可及')
for p in range(10):
craw_list_page.push(p)
craw_list_page.consume()
craw_detail_page.consume()
8.3 演示3种最常见代码思维方式爬取汽车之家资讯
演示了三种方式爬汽车之家,是骡子是马拉出来溜溜,必须精确对比。
第一种是 无框架每次临时手写全流程代码,每次临时设计手写爬虫调度全流程
第二种是 使用scrapy框架来爬取,用户要写的代码行数很多,文件很多,对于特殊独特奇葩想法极端不自由
第三种是 使用分布式函数调度框架来自动调度常规函数
8.3.1 每次临时手写rquests + 多线程,使用low爬虫方式的缺点
这样搞有以下缺点:
1、不是分布式的,不能多个脚本启动共享任务
2、不能断点爬取,即使是内置Queue改成手写使用redis的普通pop,要实现确认消费每次写一大堆代码,很难。
3、如果要调试爬虫,要反复手动自己手写添加print或log调试信息
4、写得虽然自己认为没有用爬虫框架很简洁,但导致接盘侠不知道你的代码的设计布局和意思
5、自己每次临时灵机一动搞个临时的爬虫调度设计,没有固定套路,难维护,接盘侠一个个的看每个爬虫是怎么设计布局和调度的
6、需要每次临时手写操作queue任务队列
7、需要临时手写并发
8、每次需要临时手写如何判断和添加过滤任务
9、需要临时手写怎么提取错误重试。
10、需要临时动脑筋设计怎么调度,浪费自己的时间来思考,每次都重复思考重复设计重复写爬虫全流程。
8.3.2 scrapy 爬虫框架来实现缺点
scrapy 爬虫框架来实现,(本质是Request 对象自动调度框架)
scrapy_proj_carhome 是 scrapy_redis 弄得项目,写项目需要背诵scrapy 命令行,
并且要反复在spiderxx.py settings.py items.py pipeliens.py
middwares.py push_start_urls.py run.py 7个文件里面来回切换写代码,
如果一年只临时要写一次爬虫效率很低,比low爬虫还写的慢。
需要500行,实际要手写或者修改的行数为150行,如果是写多个爬虫,平均每次实际手写的代码函数会降低一些。
8.3.3 scrapy 框架 和 分布式函数调度框架爬虫对比
不是分布式函数调度框架比scrapy爬虫框架代码质量好,主要是理念问题,
Request对象自动调度框架永远没法和函数自动调度框架的灵活自由性相比。
scrapy 自动调度 全靠 yield Request( url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None)
本质就是自动框架自动调度 Request对象,虽然入参比较丰富,大部分想法都能通过传参来搞定,但如果是一些自定义的想法,
要加到scrapy项目中就非常难。写任何一行代码都要考虑与框架的集成,
不能随便用 requests ,urllib3 ,selenium ,独立的每两个页面间的cookie自定义关联 等 乱自己来写请求,
包括换proxies要写中间件然后把类加到settings里面也是烦得要死。
比如一个很愚蠢的想法写法,在详情页解析回调这么写代码,这样瞎写完全没有考虑scrapy框架的感受。
def parse_detail_page(self, response):
driver = Chrome()
driver.get(response.url)
text = driver.page_source
scrapy框架能自动并发调度运行Request请求,但不能自动并发运行parse方法。
第一,selenium会阻塞框架。
第二,reponse本来就是一个响应结果了,他是已经被scrapy的urllib请求了,只要解析结果就好了,但这么一写有用浏览器打开一次url,
等于是请求了两次页面,这样请求两次 是嫌电脑cpu太好 还是 流量太便宜了呢。
总之使用了scrapy后就是写任何代码不能乱写,要多考虑框架的感受。
只有celery这样的函数和函数入参自动调度才能很香,
scrapy这样的固化的 Request对象入参 + 自定义中间件类添加到 settings里面的 自动调度很不自由。
分布式函数调度框架是通过把函数的入参推到队列(支持15中队列,包括语言级Queue队列 sqlite队列 redis队列 各种mq队列),
然后框架会自动从对应的队列取出任务,自动并发的运行对应的函数。函数里面怎么写那就非常自由了,你想随便有什么想法怎么写都可以,
这种方式是极端的自由和灵活,只需要按同步的思维写常规思维的函数,最后加个装饰器就能自动并发了,写函数的时候完全不用考虑框架的束缚。
任何函数都能被自动并发调度。
以下这些功能对爬虫的各种控制例如 精确的每秒爬几次 分布式中间件支持种类 消费确认 对爬虫的辅助控制远强于scrapy。
分布式:
支持数十种最负盛名的消息中间件.(除了常规mq,还包括用不同形式的如 数据库 磁盘文件 redis等来模拟消息队列)
并发:
支持threading gevent eventlet asyncio 四种并发模式 + 多进程
控频限流:
例如十分精确的指定1秒钟运行30次函数(无论函数需要随机运行多久时间,都能精确控制到指定的消费频率;
分布式控频限流:
例如一个脚本反复启动多次或者多台机器多个容器在运行,如果要严格控制总的qps,能够支持分布式控频限流。
任务持久化:
消息队列中间件天然支持
断点接续运行:
无惧反复重启代码,造成任务丢失。消息队列的持久化 + 消费确认机制 做到不丢失一个消息
定时:
可以按时间间隔、按指定时间执行一次、按指定时间执行多次,使用的是apscheduler包的方式。
指定时间不运行:
例如,有些任务你不想在白天运行,可以只在晚上的时间段运行
消费确认:
这是最为重要的一项功能之一,有了这才能肆无忌惮的任性反复重启代码也不会丢失一个任务
立即重试指定次数:
当函数运行出错,会立即重试指定的次数,达到最大次重试数后就确认消费了
重新入队:
在消费函数内部主动抛出一个特定类型的异常ExceptionForRequeue后,消息重新返回消息队列
超时杀死:
例如在函数运行时间超过10秒时候,将此运行中的函数kill
计算消费次数速度:
实时计算单个进程1分钟的消费次数,在日志中显示;当开启函数状态持久化后可在web页面查看消费次数
预估消费时间:
根据前1分钟的消费次数,按照队列剩余的消息数量来估算剩余的所需时间
函数运行日志记录:
使用自己设计开发的 控制台五彩日志(根据日志严重级别显示成五种颜色;使用了可跳转点击日志模板)
+ 多进程安全切片的文件日志 + 可选的kafka elastic日志
任务过滤:
例如求和的add函数,已经计算了1 + 2,再次发布1 + 2的任务到消息中间件,可以让框架跳过执行此任务。
任务过滤的原理是使用的是函数入参判断是否是已近执行过来进行过滤。
任务过滤有效期缓存:
例如查询深圳明天的天气,可以设置任务过滤缓存30分钟,30分钟内查询过深圳的天气,则不再查询。
30分钟以外无论是否查询过深圳明天的天气,则执行查询。
任务过期丢弃:
例如消息是15秒之前发布的,可以让框架丢弃此消息不执行,防止消息堆积,
在消息可靠性要求不高但实时性要求高的高并发互联网接口中使用
函数状态和结果持久化:
可以分别选择函数状态和函数结果持久化到mongodb,使用的是短时间内的离散mongo任务自动聚合成批量
任务后批量插入,尽可能的减少了插入次数
消费状态实时可视化:
在页面上按时间倒序实时刷新函数消费状态,包括是否成功 出错的异常类型和异常提示
重试运行次数 执行函数的机器名字+进程id+python脚本名字 函数入参 函数结果 函数运行消耗时间等
消费次数和速度生成统计表可视化:
生成echarts统计图,主要是统计最近60秒每秒的消费次数、最近60分钟每分钟的消费次数
最近24小时每小时的消费次数、最近10天每天的消费次数
rpc:
生产端(或叫发布端)获取消费结果。各个发布端对消费结果进行不同步骤的后续处理更灵活,而不是让消费端对消息的处理一干到底。
8.3.4 临时手写爬虫全流程的代码
这样搞有以下缺点: 1、不是分布式的,不能多个脚本启动共享任务 2、不能断点爬取 3、如果要调试爬虫,要反复手动自己手写添加print或log调试 4、写得虽然自己认为没有用爬虫框架很简洁,但导致接盘侠不知道你的代码的设计布局和意思 5、自己每次临时灵机一动搞个临时的爬虫调度设计,没有固定套路,难维护,接盘侠一个个的看每个爬虫是怎么设计布局和调度的 6、需要每次临时手写操作queue任务队列 7、需要临时手写并发 8、每次需要临时手写如何判断和添加过滤任务 9 需要临时手写怎么提取错误重试。 10、需要临时动脑筋设计怎么调度,浪费自己的时间来思考
from queue import Queue, Empty
import time
import requests
from urllib3 import disable_warnings
from parsel import Selector
from concurrent.futures import ThreadPoolExecutor
from threading import Thread
import redis
disable_warnings()
queue_list_page = Queue(1000)
queue_detail_page = Queue(1000)
pool_list_page = ThreadPoolExecutor(30)
pool_detail_page = ThreadPoolExecutor(100)
# detail_task_filter_set = set()
r = redis.Redis()
def crawl_list_page(news_type, page):
def _run_list_page_retry(current_retry_times):
try:
url = f'https://www.autohome.com.cn/{news_type}/{page}/#liststart'
print(f'请求的列表页url是 {url}')
resp = requests.request('get', url, timeout=5)
if resp.status_code != 200:
raise ValueError
resp_text = resp.content.decode('gbk')
sel = Selector(resp_text)
for li in sel.css('#Ul1 > li'):
url = 'https:' + li.xpath('./a/@href').extract_first()
title = li.xpath('./a/h3/text()').extract_first()
task = (url, title)
print('向详情页队列添加任务:', task)
queue_detail_page.put(task)
if page == 1:
last_page = int(sel.css('#channelPage > a:nth-child(12)::text').extract_first())
for p in range(2, last_page + 1):
task = (news_type, p)
print('向列表页页队列添加任务:', task)
queue_list_page.put(task)
except Exception as e:
print(f'第{current_retry_times}次爬取列表页出错', e.__traceback__, e)
if current_retry_times < 5:
_run_list_page_retry(current_retry_times + 1)
else:
print('重试了5次仍然错误')
_run_list_page_retry(1)
def crawl_detail_page(url, title):
def _run_detail_page_retry(current_retry_times):
if r.sismember('filter_carhome_detail_page', url):
print(f'此入参已经爬取过了 {url} {title}')
return
else:
try:
print(f'请求的详情页url是 {url}')
resp = requests.request('get', url, timeout=5)
if resp.status_code != 200:
raise ValueError
resp_text = resp.content.decode('gbk')
sel = Selector(resp_text)
author = sel.css('#articlewrap > div.article-info > div > a::text').extract_first() or
sel.css('#articlewrap > div.article-info > div::text').extract_first() or ''
author = author.replace("\n", "").strip()
print(f'{time.strftime("%H:%M:%S")} 保存到数据库 {url} {title} {author} ')
r.sadd('filter_carhome_detail_page', url) # 运行成功了,放入过滤中
except Exception as e:
print(f'第{current_retry_times}次爬取详情页页出错', e.__traceback__, e)
if current_retry_times < 3:
_run_detail_page_retry(current_retry_times + 1)
else:
print('重试了3次仍然错误')
r.sadd('filter_carhome_detail_page', url) # 运行最大次数了,放入过滤中
_run_detail_page_retry(1)
def start_list_page():
while True:
try:
task = queue_list_page.get(block=True, timeout=600)
print(f'取出的列表页爬取任务是 {task}')
pool_list_page.submit(crawl_list_page, *task)
except Empty:
print('列表页超过600秒没有任务,列表页爬完了')
break
def start_detail_page():
while True:
try:
task = queue_detail_page.get(block=True, timeout=600)
print(f'取出的详情页爬取任务是 {task}')
pool_detail_page.submit(crawl_detail_page, *task)
except Empty:
print('详情页超过600秒没有任务,详情页爬完了')
break
if __name__ == '__main__':
# 单独的测试函数功能
# crawl_list_page('advice',1) #
# crawl_detail_page('https://www.autohome.com.cn/news/202008/1022380.html#pvareaid=102624','xxx')
t1 = Thread(target=start_list_page)
t2 = Thread(target=start_detail_page)
t1.start()
t2.start()
queue_list_page.put(('news', 1)) # 新闻
queue_list_page.put(('advice', 1)) # 导购
queue_list_page.put(('drive', 1)) # 评测
举个网上下载 mzitu 网站图片的代码截图,就是采用的无框架爬虫,任务调度靠直接for循环调用函数,任务并发全靠手写操作threads,
这样的代码看起来很多很混乱,写一个还行,要是爬虫项目多了,没有统一化的逻辑思维,接盘侠每次都要阅读很长的代码才知道运行逻辑,那就非常悲催。
 img_13.png
img_13.png
8.3.5 scrapy爬虫代码
这是scrapy爬虫代码的基本结构,用户写代码需要非常频繁的在 spider items middware pipeline settings cmd命令行 来回切换写代码测试代码,很吓人。
需要在不同的地方写middleware类 pipeline类并把类名添加到settings里面。
scrapy目录结构,代码文件数量很多
 img_5.png
img_5.png
这是 scrapy carhome_spider.py的代码
# This package will contain the spiders of your Scrapy project
#
# Please refer to the documentation for information on how to create and manage
# your spiders.
import json
from scrapy.http import Request
from scrapy_redis.spiders import RedisSpider
from scrapy_proj_carhome.items import ScrapyProjCarhomeItem
import nb_log
class carHomeSpider(RedisSpider):
name = "carhome"
allowed_domains = ["www.autohome.com.cn"]
redis_key = "carhome:start_urls"
def make_requests_from_url(self, data: str):
'''
data就是放入 carhome:start_urls 中的任务,因为最初的种子信息还需要携带其他信息,例如新闻类型的中文种类,不是单纯的url,所以需要重写此方法
:param data:
:return:
'''
start_task = json.loads(data)
url = start_task['url']
# 此处也可以改为post请求
return Request(
url,
meta=start_task
)
def parse(self, response):
# https://www.autohome.com.cn/news/2/#liststart
# print(response.body)
for li in response.css('#Ul1 > li'):
url = 'https:' + li.xpath('./a/@href').extract_first()
title = li.xpath('./a/h3/text()').extract_first()
yield Request(url, callback=self.parse_detail_page, meta={'url': url, 'title': title, 'news_type': response.meta['news_type']},
dont_filter=False, priority=10)
page = response.url.split('/')[-2]
if page == '1':
last_page = int(response.css('#channelPage > a:nth-child(12)::text').extract_first())
for p in range(2, last_page + 1):
url_new = response.url.replace('/1/', f'/{p}/')
self.logger.debug(url_new)
yield Request(url_new, callback=self.parse, dont_filter=True, meta=response.meta)
def parse_detail_page(self, response):
author = response.css('#articlewrap > div.article-info > div > a::text').extract_first() or
response.css('#articlewrap > div.article-info > div::text').extract_first() or ''
author = author.replace("\n", "").strip()
item = ScrapyProjCarhomeItem()
item['author'] = author
item['url'] = response.meta['url']
item['title'] = response.meta['title']
item['news_type'] = response.meta['news_type']
yield item
if __name__ == '__main__':
pass
这是 items.py 的代码
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapyProjCarhomeItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
author = scrapy.Field()
url = scrapy.Field()
title = scrapy.Field()
news_type = scrapy.Field()
这个文件的代码是最坑的,任何自定义想法需要写一个类,继承middware类,重写process_request process_request方法,然后把类名添加到settings里面。
这是 middlewares.py的代码
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
class ScrapyProjCarhomeSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Response, dict
# or Item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class ScrapyProjCarhomeDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
这是pipelines.py 的代码,保存数据。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy_proj_carhome.items import ScrapyProjCarhomeItem
class ScrapyProjCarhomePipeline(object):
def process_item(self, item, spider):
print(type(item))
if isinstance(item, ScrapyProjCarhomeItem):
print(f'保存到数据库 {item["news_type"]} {item["url"]} {item["title"]} {item["author"]} ')
return item
这是settings.py的代码
# -*- coding: utf-8 -*-
# Scrapy settings for scrapy_proj_carhome project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'scrapy_proj_carhome'
SPIDER_MODULES = ['scrapy_proj_carhome.spiders']
NEWSPIDER_MODULE = 'scrapy_proj_carhome.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = 'scrapy_proj_carhome (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
# DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
# CONCURRENT_REQUESTS_PER_DOMAIN = 16
# CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
# COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
# TELNETCONSOLE_ENABLED = False
# Override the default request headers:
# DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
# }
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
# SPIDER_MIDDLEWARES = {
# 'scrapy_proj_carhome.middlewares.ScrapyProjCarhomeSpiderMiddleware': 543,
# }
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'scrapy_proj_carhome.middlewares.ScrapyProjCarhomeDownloaderMiddleware': 543,
}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
# EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
# }
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scrapy_proj_carhome.pipelines.ScrapyProjCarhomePipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
# AUTOTHROTTLE_ENABLED = True
# The initial download delay
# AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
# AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
# AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
# AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
# HTTPCACHE_ENABLED = True
# HTTPCACHE_EXPIRATION_SECS = 0
# HTTPCACHE_DIR = 'httpcache'
# HTTPCACHE_IGNORE_HTTP_CODES = []
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
REDIS_HOST = "127.0.0.1"
REDIS_PORT = 6379
REDIS_PARAMS = {'db': 2, 'password': ''}
REDIS_ENCODING = "utf-8"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER_PERSIST = True
# DUPEFILTER_KEY = "dupefilter:%(timestamp)s"
这是 push_start_urls.py 的代码
from redis import Redis
import json
from scrapy_proj_carhome import settings
r = Redis(host=settings.REDIS_HOST, port=settings.REDIS_PORT, **settings.REDIS_PARAMS)
r.flushdb()
# 因为要让初始种子就携带其他信息,初始种子发布的不是url本身,所以需要继承重写spider的make_requests_from_url方法。
r.lpush('carhome:start_urls', json.dumps({'url': 'https://www.autohome.com.cn/news/1/#liststart', 'news_type': '新闻'}, ensure_ascii=False))
r.lpush('carhome:start_urls', json.dumps({'url': 'https://www.autohome.com.cn/advice/1/#liststart', 'news_type': '导购'}, ensure_ascii=False))
r.lpush('carhome:start_urls', json.dumps({'url': 'https://www.autohome.com.cn/drive/1/#liststart', 'news_type': '驾驶评测'}, ensure_ascii=False))
这是run.py的代码
from scrapy import cmdline
cmdline.execute(['scrapy', 'crawl', 'carhome'])
从上面的代码可以看到scrapy要在8个文件频繁的来回切换写代码,非常的烦躁。
即使是除去scrapy 建项目自动生产的固定代码行数,此scrapy项目的代码行数仍然远远高于分布式函数调度框架的代码行数
8.3.6 分布式函数调度框架的代码
只需要单个文件(当然也可以拆解成发布和消费独立成两个文件)
所需代码行数远小于无框架每次临时手写爬虫全流程和使用scrapy的方式。
此框架不仅可以对标celery框架,也可以取代scrapy框架。
from function_scheduling_distributed_framework import task_deco, BrokerEnum
import requests
from parsel import Selector
@task_deco('car_home_list', broker_kind=BrokerEnum.REDIS_ACK_ABLE, max_retry_times=5, qps=10)
def crawl_list_page(news_type, page):
url = f'https://www.autohome.com.cn/{news_type}/{page}/#liststart'
resp_text = requests.get(url).text
sel = Selector(resp_text)
for li in sel.css('#Ul1 > li'):
url_detail = 'https:' + li.xpath('./a/@href').extract_first()
title = li.xpath('./a/h3/text()').extract_first()
crawl_detail_page.push(url_detail, title=title, news_type=news_type)
if page == 1:
last_page = int(sel.css('#channelPage > a:nth-child(12)::text').extract_first())
for p in range(2, last_page + 1):
crawl_list_page.push(news_type, p)
@task_deco('car_home_detail', broker_kind=BrokerEnum.REDIS_ACK_ABLE, concurrent_num=100, qps=30, do_task_filtering=False)
def crawl_detail_page(url, title, news_type):
resp_text = requests.get(url).text
sel = Selector(resp_text)
author = sel.css('#articlewrap > div.article-info > div > a::text').extract_first() or
sel.css('#articlewrap > div.article-info > div::text').extract_first() or ''
author = author.replace("\n", "").strip()
print(f'使用print模拟保存到数据库 {news_type} {title} {author} {url}') # ,实际为调用数据库插入函数,压根不需要return item出来在另外文件的地方进行保存。
if __name__ == '__main__':
# 单独的测试函数功能
# crawl_list_page('advice',1) #
# crawl_detail_page('https://www.autohome.com.cn/news/202008/1022380.html#pvareaid=102624','xxx')
# 清空消息队列
crawl_list_page.clear()
crawl_detail_page.clear()
#
# # 推送列表页首页
crawl_list_page.push('news', 1) # 新闻
crawl_list_page.push('advice', page=1) # 导购
crawl_list_page.push(news_type='drive', page=1) # 驾驶评测
# 启动列表页消费和详情页消费,上面的清空和推送可以卸载另外的脚本里面,因为是使用的中间件解耦,所以可以推送和消费独立运行。
crawl_list_page.consume()
crawl_detail_page.consume()
使用分布式函数调度框架运行的爬虫,自动并发,自动控频,是指定了列表页qps=2,详情页qps=3的情况下运行的控制台日志
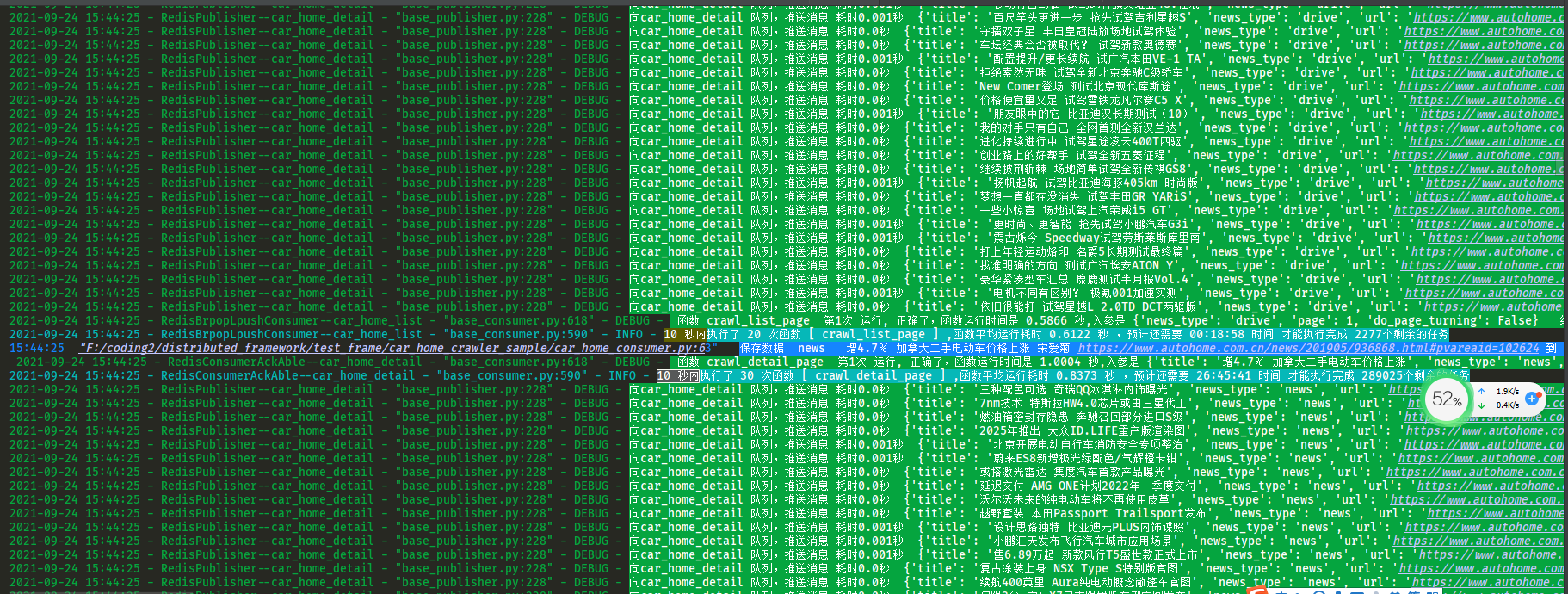 4BquHf.png
4BquHf.png可以得出结论,控频效果精确度达到了99%以上,目前世界所有爬虫框架只能指定并发请求数量,但不能指定每秒爬多少次页面,此框架才能做到。