2. 对比celery框架
是骡子是马必须拿出来溜溜。
此章节对比celery和分布式函数调度框架,是采用最严格的控制变量法精准对比。
例如保持 中间件一致 控制参数一致 并发类型一致 并发数量一致等等,变化的永远只有采用什么框架。
2.0,在比较之前,说明一下和celery的关系?
此框架和celery没有关系,没有收到celery启发,也不可能找出与celery连续3行一模一样的代码。
这个是从原来项目代码里面大量重复while 1:redis.blpop() 发散扩展的。
这个和celery唯一有相同点是,都是生产者 消费者 + 消息队列中间件的模式,这种生产消费的编程思想或者叫想法不是celery的专利。
包括我们现在java框架实时处理数据的,其实也就是生产者 消费者加kfaka中间件封装的,难道java人员也是需要模仿python celery源码吗。
任何人都有资格开发封装生产者消费者模式的框架,生产者 消费者模式不是celery专利。生产消费模式很容易想到,不是什么高深的架构思想,不需要受到celery的启发才能开发。
2.1 celery对目录层级文件名称格式要求很高
celery对目录层级文件名称格式要求太高,只适合规划新的项目,对不规则文件夹套用难度高。
所以新手使用celery很仔细的建立文件夹名字、文件夹层级、python文件名字
所以网上的celery博客教程虽然很多,但是并不能学会使用,因为要运行起来需要以下6个方面都掌握好,博客文字很难表达清楚或者没有写全面以下6个方面。 celery消费任务不执行或者报错NotRegistered,与很多方面有关系,如果要别人排错,至少要发以下6方面的截图,
1) 整个项目目录结构,celery的目录结构和任务函数位置,有很大影响
2) @task入参 ,用户有没有主动设置装饰器的入参 name,设置了和没设置有很大不同,建议主动设置这个名字对函数名字和所处位置依赖减小
3) celery的配置,task_queues(在3.xx叫 CELERY_QUEUES )和task_routes (在3.xx叫 task_routes)
4) celery的配置 include (在3.xx叫 CELERY_INCLUDE)或者 imports (3.xx CELERY_IMPORTS) 或者 app.autodiscover_tasks的入参
5) cmd命令行启动参数 --queues= 的值
6) 用户在启动cmd命令行时候,用户所在的文件夹。
(如果不精通这个demo的,使用cmd命令行启动时候,用户必须cd切换到当前python项目的根目录,
如果精通主动自己设置PYTHONPATH和精通此demo,可以在任何目录下启动celery命令行或者不使用celery命令行而是调用app.work_main()启动消费
在不规范的文件夹路径下,使用celery难度很高,一般教程都没教。 项目文件夹目录格式不规范下的celery使用演示
分布式函数调度框架天生没有这些方面的问题,因为此框架实现分布式消费的写法简单很多。
如你所见,使用此框架为什么没有配置中间件的 账号 密码 端口号呢。只有运行任何一个导入了框架的脚本文件一次,就会自动生成一个配置文件
然后在配置文件中按需修改需要用到的配置就行。
@task_deco 和celery的 @app.task 装饰器区别很大,导致写代码方便简化容易很多。没有需要先实例化一个 Celery对象一般叫app变量,
然后任何脚本的消费函数都再需要导入这个app,然后@app.task,一点小区别,但造成的两种框架写法难易程度区别很大。
使用此框架,不需要固定的项目文件夹目录,任意多层级深层级文件夹不规则python文件名字下写函数都行,
celery 实际也可以不规则文件夹和文件名字来写任务函数,但是很难掌握,如果这么写的话,那么在任务注册时候会非常难,
一般demo演示文档都不会和你演示这种不规则文件夹和文件名字下写celery消费函数情况,因为如果演示这种情况会非常容易的劝退绝大部分小白。
但是如果不精通celery的任务注册导入机制同时又没严格按照死板固定的目录格式来写celery任务,
一定会出现令人头疼的 Task of kind 'tasks.add' is not registered, please make sure it's imported. 类似这种错误。
主要原因是celery 需要严格Celery类的实例化对象app变量,然后消费函数所在脚本必须import这个app,这还没完,
你必须在settings配置文件写 include imports 等配置,否则cmd 启动celery 后台命令时候,celery并不知情哪些文件脚本导入了 app这个变量,
当celery框架取出到相关的队列任务时候,就会报错找不到应该用哪个脚本下的哪个函数去运行取出的消息了。
你可能会想,为什么celery app 变量的脚本为什么不可以写导入消费函数的import声明呢,比如from dir1.dir2.pyfilename imprt add 了,
这样celery运行时候就能找到函数了是不是?那要动脑子想想,如果celery app主文件用了 from dir1.dir2.pyfilename import add,
同时消费函数 add 所在的脚本 dir1/dir2/pyfilename.py 又从celery app的猪脚本中导入app,然后把@app.task加到add函数上面 ,
那这就是出现了互相导入,a导入b,b导入a的问题了,脚本一启动就报错,正是因为这个互相导入的问题,
celery才需要从配置中写好 include imports autodiscover_tasks,从而实现一方延迟导入以解决互相导入。
此框架的装饰器不存在需要一个类似Celery app实例的东西,不会有这个变量将大大减少编程难度,消费函数写在任意深层级不规则文件下都行。
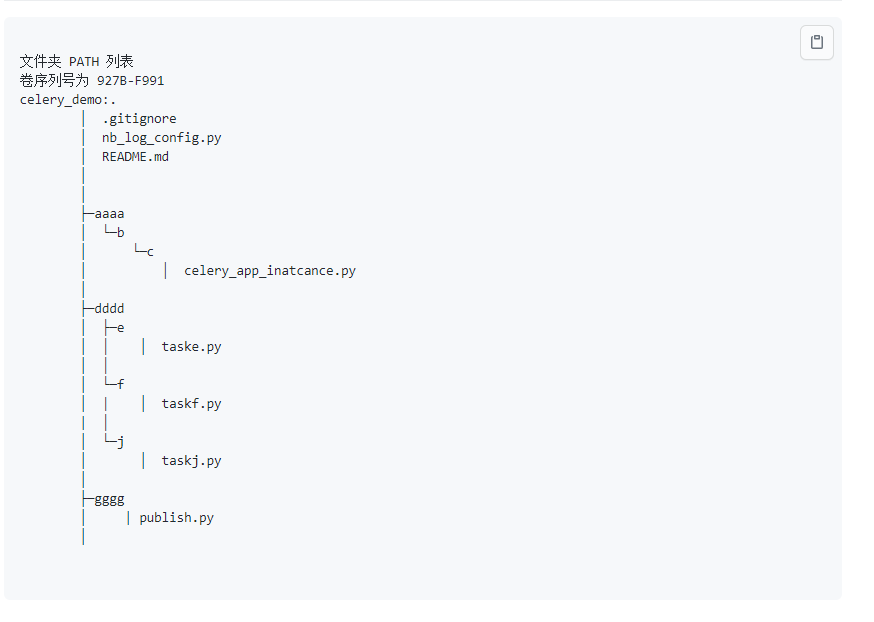
例如董伟明的 celery 教程例子的项目目录结构,然后很多练习者需要小心翼翼模仿文件夹层级和py文件名字。
 img_4.png
img_4.png
可以看代码,当文件夹层级不规则和文件名称不规则时候,要使用celery绝非简单事情,如果你只看普通的celery入门文档,是绝对解决不了
这种情况下的celery如何正确使用。
 img.png
img.png
2.2 性能远远超过celery
任意并发模式,任意中间件类型,发布和消费性能远远超过celery
 img_2.png
img_2.png
2.3 celery的重要方法全部无法ide自动补全提示
函数调度框架为了代码在ide能自动补全做了额外优化,celery全部重要公有方法无法补全提示.
1、配置文件方式的代码补全,此框架使用固定的项目根目录下的 distributed_frame_config.py 补全, 不会造成不知道有哪些配置项可以配置,celery的配置项有100多个,用户不知道能配置什么。 2、启动方式补全,celery采用celery -A celeryproj work + 一大串cmd命令行,很容易打错字母,或者不知道 celery命令行可以接哪些参数。次框架使用 fun.consume()/fun.multi_process_consume()启动消费, 运行直接 python xx.py方式启动 3、发布参数补全,对于简单的只发布函数入参,celery使用delay发布,此框架使用push发布,一般delay5个字母不会敲错。 对于除了需要发布函数入参还要发布函数任务控制配置的发布,此框架使用publish不仅可以补全函数名本身还能补全函数入参。 celery使用 add.apply_async 发布,不仅apply_async函数名本身无法补全,最主要是apply_async入参达到20种,不能补全 的话造成完全无法知道发布任务时候可以传哪些任务控制配置,无法补全时候容易敲错入参字母,导致配置没生效。 举个其他包的例子是例如 requests.get 函数,由于无法补全如果用户把headers写成header或者haeders,函数不能报错导致请求头设置无效。 此框架的发布publish方法不仅函数名本身可以补全,发布任务控制的配置也都可以补全。 4、消费任务函数装饰器代码补全,celery使用@app.task,源码入参是 def task(self, *args, **opts),那么args和opts到底能传什么参数, 从方法本身的注释来看无法找到,即使跳转到源码去也没有说明,task能传什么参数,实际上可以传递大约20种参数,主要是任务控制参数。 此框架的@task_deco装饰器的 20个函数入参和入参类型全部可以自动补全提示,以及入参意义注释使用ctrl + shift + i 快捷键可以看得很清楚。 5、此框架能够在pycharm下自动补全的原因主要是适当的做了一些调整,以及主要的面向用户的公有方法宁愿重复声明入参,也不使用*args **kwargs这种。 举个例子说明是 @task_deco这个装饰器(这里假设装饰到fun函数上), 此装饰器的入参和get_consumer工厂函数一模一样,但是为了补全方便没有采用*args **kwargs来达到精简源码的目的, 因为这个装饰器是真个框架最最最重要的,所以这个是重复吧所有入参都声明了一遍。 对于被装饰的消费函数,此装饰器会自动动态的添加很多方法和属性,附着到被装饰的任务函数上面。 这些动态运行时添加到 fun函数的,pycharm本来是无法自动补全提示的,但框架对_deco内部函数返回值添加了一个返回类型声明 -> IdeAutoCompleteHelper, IdeAutoCompleteHelper这个对象具有的方法方法和属性都使用# type: 语法注释了类型,而且所有属性和方法刚好是附着到fun上面的方法和属性, 所以类似fun.clear fun.publish fun.consume fun.multi_process_conusme 这些方法名本身和他的入参都能够很好的自动补全。 6、自动补全为什么重要?对于入参丰富动不动高达20种入参,且会被频繁使用的重要函数,如果不能自动补全,用户无法知道有哪些方法名 方法能传什么参数 或 者敲了错误的方法名和入参。如果自动补全不重要,那为什么不用vim和txt写python代码,说不重要的人,那以后就别用pycharm vscode这些ide写代码。 celery的复杂难用,主要是第一个要求的目录文件夹格式严格,对于新手文件夹层级 名字很严格,必须小心翼翼模仿。 第二个是列举的1 2 3 4这4个关键节点的代码补全,分别是配置文件可以指定哪些参数、命令行启动方式不知道可以传哪些参数、apply_async可以传哪些参数、 @app.task的入参代码补全,最重要的则4个流程节点的代码全都无法补全,虽然是框架很强大但是也很难用。
2.4 比celery强的方面的优势大全
0)celer4 以后官方放弃对windwos的支持和测试,例如celery的默认多进程模式在windwos启动瞬间就会报错,
虽然生产一般是linux,但开发机器一般是windwos。
1) 如5.4所写,新增了python内置 queue队列和 基于本机的持久化消息队列。不需要安装中间件,即可使用。
只要是celery能支持的中间件,这个全部能支持。因为此框架的 BrokerEnum.KOMBU 中间件模式一次性
支持了celery所能支持的所有中间件。但celery不支持kafka、nsq、mqtt、zeromq、rocketmq等。
2) 任意中间件和并发模式,发布和消费性能比celery框架远远的大幅度提高。
4) 全部公有方法或函数都能在pycharm智能能提示补全参数名称和参数类型。
一切为了调用时候方便而不是为了实现时候简略,例如get_consumer函数和AbstractConsumer的入参完全重复了,
本来实现的时候可以使用*args **kwargs来省略入参,
但这样会造成ide不能补全提示,此框架一切写法只为给调用者带来使用上的方便。不学celery让用户不知道传什么参数。
如果拼错了参数,pycharm会显红,大大降低了用户调用出错概率。过多的元编程过于动态,不仅会降低性能,还会让ide无法补全提示,动态一时爽,重构火葬场不是没原因的。
5)不使用命令行启动,在cmd打那么长的一串命令,容易打错字母。并且让用户不知道如何正确的使用celery命令,不友好。
此框架是直接python xx.py 就启动了。
6)框架不依赖任何固定的目录结构,无结构100%自由,想把使用框架写在哪里就写在哪里,写在10层级的深层文件夹下都可以。
脚本可以四处移动改名。celery想要做到这样,要做额外的处理。
7)使用此框架比celery更简单10倍,如例子所示。使用此框架代码绝对比使用celery少几十行。
8)消息中间件里面存放的消息任务很小,简单任务 比celery的消息小了50倍。 消息中间件存放的只是函数的参数,
辅助参数由consumer自己控制。消息越小,中间件性能压力越小。
9)由于消息中间件里面没有存放其他与python 和项目配置有关的信息,这是真正的跨语言的函数调度框架。
java人员也可以直接使用java的redis类rabbitmq类,发送json参数到中间件,由python消费。
celery里面的那种参数,高达几十项,和项目配置混合了,java人员绝对拼凑不出来这种格式的消息结构。
10)celery有应该中心化的celery app实例,函数注册成任务,添加装饰器时候先要导入app,然后@app.task,
同时celery启动app时候,调度函数就需要知道函数在哪里,所以celery app所在的py文件也是需要导入消费函数的,否则会
celery.exceptions.NotRegistered报错
这样以来就发生了务必蛋疼的互相导入的情况,a要导入b,b要导入a,这问题太令人窘迫了,通常解决这种情况是让其中一个模块后导入,
这样就能解决互相导入的问题了。celery的做法是,使用imports一个列表,列表的每一项是消费函数所在的模块的字符串表示形式,
例如 如果消费函数f1在项目的a文件夹下的b文件夹下的c.py中,消费函数与f2在项目的d文件夹的e.py文件中,
为了解决互相导入问题,celery app中需要配置 imports = ["a.b.c",'d.e'],这种import在pycharm下容易打错字,
例如scrapy和django的中间件注册方式,也是使用的这种类似的字符串表示导入路径,每添加一个函数,只要不在之前的模块中,就要这么写,
不然不写improt的话,那是调度不了消费函数的。此框架原先没有装饰器方式,来加的装饰器方式与celery的用法大不相同,
因为没有一个叫做app类似概念的东西,不需要相互导入,启动也是任意文件夹下的任意脚本都可以,自然不需要写什么imports = ['a.b.c']
11)简单利于团队推广,不需要看复杂的celry 那样的5000页英文文档,因为函数调度框架只需要学习@task_deco一个装饰器,只有一行代码。
对于不规则文件夹项目的clery使用时如何的麻烦,可以参考 celery_demo项目 https://github.com/ydf0509/celery_demo。
12)此框架原生支持 asyncio 原始函数,不用用户额外处理 asyncio loop相关麻烦的问题。celery不支持async定义的函数,celery不能把@app.task
加到一个async def 的函数上面。
13) 这是最重要的,光使用简单还不够,性能是非常重要的指标。
此框架消息发布性能和消息消费性能远远超过celery数十倍。为此专门开了一个对比项目,发布和消费10万任务,
对分布式函数调度框架和celery进行严格的控制变量法来benchmark,分别测试两个框架的发布和消费性能。
对比项目在此,可以直接拉取并分别运行两个项目的发布和消费一共4个脚本。
https://github.com/ydf0509/distrubuted_framework_vs_celery_benchmark
14) 此框架比celery对函数的辅助运行控制方式更多,支持celery的所有如 并发 控频 超时杀死 重试 消息过期
确认消费 等一切所有功能,同时包括了celery没有支持的功能,例如原生对函数入参的任务过滤等。
15) celery不支持分布式全局控频,celery的rate_limit 基于单work控频,如果把脚本在同一台机器启动好几次,
或者在多个容器里面启动消费,那么总的qps会乘倍数增长。此框架能支持单个消费者控频,同时也支持分布式全局控频。
16) 此框架比celery更简单开启 多进程 + 线程或协程。celery的多进程和多线程是互斥的并发模式,此框架是叠加的。
很多任务都是需要 多进程并发利用多核 + 细粒度的线程/协程绕过io 叠加并发 ,才能使运行速度更快。
17) 此框架精确控频率精确度达到99.9%,celery控频相当不准确,最多到达60%左右,两框架同样是做简单的加法然后sleep0.7秒,都设置500并发100qps。
测试对比代码见qps测试章节,欢迎亲自测试证明。
18) celery不支持分布式全局控频,只支持当前解释器的控频。
19) 日志的颜色和格式,远超celery。此框架的日志使用nb_log,日志在windwos远超celery,在linux也超过celery很多。