4.使用框架的各种代码示例
框架极其简单并且自由,只有一个task_deco装饰器的参数学习, 实际上这个章节所有的例子都是调整了一下task_deco的参数而已。
有一点要说明的是框架的消息中间件的ip 端口 密码 等配置是在你第一次随意运行代码时候,在你当前项目的根目录下生成的 distributed_frame_config.py 按需设置。
所有例子的发布和消费都没必须写在同一个py文件,(除了使用python 自带语言queue),因为是使用中间件解耦的消息,好多人误以为发布和消费必须在同一个python文件。
4.1 装饰器方式调度函数
from function_scheduling_distributed_framework import task_deco, BrokerEnum
# qps可以指定每秒运行多少次,可以设置0.001到10000随意。
# broker_kind 指定使用什么中间件,如果用redis,就需要在 distributed_frame_config.py 设置redis相关的配置。
@task_deco('queue_test_f01', qps=0.2, broker_kind=BrokerEnum.REDIS_ACK_ABLE) # qps 0.2表示每5秒运行一次函数,broker_kind=2表示使用redis作中间件。
def add(a, b):
print(a + b)
if __name__ == '__main__':
for i in range(10, 20):
add.pub(dict(a=i, b=i * 2)) # 使用add.pub 发布任务
add.push(i, b=i * 2) # 使用add.push 发布任务
add.consume() # 使用add.consume 消费任务
# add.multi_process_consume(4) # 这是开启4进程 叠加 细粒度(协程/线程)并发,速度更强。
4.2 非装饰器调度函数
from function_scheduling_distributed_framework import get_consumer, BrokerEnum
def add(a, b):
print(a + b)
# 非装饰器方式,多了一个入参,需要手动指定consuming_function入参的值。
consumer = get_consumer('queue_test_f01', consuming_function=add, qps=0.2, broker_kind=BrokerEnum.REDIS_ACK_ABLE)
if __name__ == '__main__':
for i in range(10, 20):
consumer.publisher_of_same_queue.publish(dict(a=i, b=i * 2)) # consumer.publisher_of_same_queue.publish 发布任务
consumer.start_consuming_message() # 使用consumer.start_consuming_message 消费任务
4.3 演示如何解决多个步骤的消费函数
看这个例子,step1函数中不仅可以给step2发布任务,也可以给step1自身发布任务。
qps规定了step1每2秒执行一次,step2每秒执行3次。
import time
from function_scheduling_distributed_framework import task_deco, BrokerEnum
@task_deco('queue_test_step1', qps=0.5, broker_kind=BrokerEnum.LOCAL_PYTHON_QUEUE)
def step1(x):
print(f'x 的值是 {x}')
if x == 0:
for i in range(1, 300):
step1.pub(dict(x=x + i))
for j in range(10):
step2.push(x * 100 + j) # push是直接发送多个参数,pub是发布一个字典
time.sleep(10)
@task_deco('queue_test_step2', qps=3, broker_kind=BrokerEnum.LOCAL_PYTHON_QUEUE)
def step2(y):
print(f'y 的值是 {y}')
time.sleep(10)
if __name__ == '__main__':
# step1.clear()
step1.push(0) # 给step1的队列推送任务。
step1.consume() # 可以连续启动两个消费者,因为conusme是启动独立线程里面while 1调度的,不会阻塞主线程,所以可以连续运行多个启动消费。
step2.consume()
4.4 演示如何定时运行。
# 定时运行消费演示,定时方式入参用法可以百度 apscheduler 定时包。
import datetime
from function_scheduling_distributed_framework import task_deco, BrokerEnum, fsdf_background_scheduler, timing_publish_deco
@task_deco('queue_test_666', broker_kind=BrokerEnum.LOCAL_PYTHON_QUEUE)
def consume_func(x, y):
print(f'{x} + {y} = {x + y}')
if __name__ == '__main__':
fsdf_background_scheduler.add_job(timing_publish_deco(consume_func), 'interval', id='3_second_job', seconds=3, kwargs={"x": 5, "y": 6}) # 每隔3秒发布一次任务,自然就能每隔3秒消费一次任务了。
fsdf_background_scheduler.add_job(timing_publish_deco(consume_func), 'date', run_date=datetime.datetime(2020, 7, 24, 13, 53, 6), args=(5, 6,)) # 定时,只执行一次
fsdf_background_scheduler.add_timing_publish_job(consume_func, 'cron', day_of_week='*', hour=14, minute=51, second=20, args=(5, 6,)) # 定时,每天的11点32分20秒都执行一次。
# 启动定时
fsdf_background_scheduler.start()
# 启动消费
consume_func.consume()
4.5 多进程并发 + 多线程/协程,代码例子。
ff.multi_process_start(2) 就是代表启动2个独立进程并发 + 叠加 asyncio、gevent、eventlet、threding细粒度并发,
例如fun函数加上@task_deco(concurrent_num=200),fun.multi_process_start(16) ,这样16进程叠加每个进程内部开200线程/协程,运行性能炸裂。
多进程消费
import time
from function_scheduling_distributed_framework import task_deco, BrokerEnum, IdeAutoCompleteHelper, PriorityConsumingControlConfig, run_consumer_with_multi_process
"""
演示多进程启动消费,多进程和 asyncio/threading/gevnt/evntlet是叠加关系,不是平行的关系。
"""
# qps=5,is_using_distributed_frequency_control=True 分布式控频每秒执行5次。
# 如果is_using_distributed_frequency_control不设置为True,默认每个进程都会每秒执行5次。
@task_deco('test_queue', broker_kind=BrokerEnum.REDIS, qps=5, is_using_distributed_frequency_control=True)
def ff(x, y):
import os
time.sleep(2)
print(os.getpid(), x, y)
if __name__ == '__main__':
ff.clear() # 清除
# ff.publish()
for i in range(1000):
ff.push(i, y=i * 2)
# 这个与push相比是复杂的发布,第一个参数是函数本身的入参字典,后面的参数为任务控制参数,例如可以设置task_id,设置延时任务,设置是否使用rpc模式等。
ff.publish({'x': i * 10, 'y': i * 2}, priority_control_config=PriorityConsumingControlConfig(countdown=1, misfire_grace_time=15))
ff(666, 888) # 直接运行函数
ff.start() # 和 conusme()等效
ff.consume() # 和 start()等效
run_consumer_with_multi_process(ff, 2) # 启动两个进程
ff.multi_process_start(2) # 启动两个进程,和上面的run_consumer_with_multi_process等效,现在新增这个multi_process_start方法。
IdeAutoCompleteHelper(ff).multi_process_start(3) # IdeAutoCompleteHelper 可以补全提示,但现在装饰器加了类型注释,ff. 已近可以在pycharm下补全了。
4.6 演示rpc模式,即客户端调用远程函数并及时得到结果。
如果在发布端要获取消费端的执行结果,有两种方式
1、需要在@task_deco设置is_using_rpc_mode=True,默认是False不会得到结果。
2、如果@task_deco没有指定,也可以在发布任务的时候,用publish方法并写上
priority_control_config=PriorityConsumingControlConfig(is_using_rpc_mode=True)
1)远程服务端脚本,执行求和逻辑。 test_frame\test_rpc\test_consume.py
import time
from function_scheduling_distributed_framework import task_deco, BrokerEnum
@task_deco('test_rpc_queue', is_using_rpc_mode=True, broker_kind=BrokerEnum.REDIS_ACK_ABLE,concurrent_num=200)
def add(a, b):
time.sleep(3)
return a + b
if __name__ == '__main__':
add.consume()
2.1)客户端调用脚本,单线程发布阻塞获取两书之和的结果,执行求和过程是在服务端。 test_frame\test_rpc\test_publish.py
这种方式如果在主线程单线程for循环运行100次,因为为了获取结果,导致需要300秒才能完成100次求和。
from function_scheduling_distributed_framework import PriorityConsumingControlConfig
from test_frame.test_rpc.test_consume import add
for i in range(100):
async_result = add.push(i, i * 2)
print(async_result.result) # 执行 .result是获取函数的运行结果,会阻塞当前发布消息的线程直到函数运行完成。
# 如果add函数的@task_deco装饰器参数没有设置 is_using_rpc_mode=True,则在发布时候也可以指定使用rpc模式。
async_result = add.publish(dict(a=i * 10, b=i * 20), priority_control_config=
PriorityConsumingControlConfig(is_using_rpc_mode=True))
print(async_result.status_and_result)
2.2) 设置rpc回调结果在线程池中处理
上面2.1)方式中是在单线程环境下阻塞的一个接一个打印结果。如果想快速并发处理结果,可以自己手动在多线程或线程池处理结果。 框架也提供一个设置回调函数,自动在线程池中处理回调结果,回调函数有且只有一个入参,表示函数运行结果及状态。
如下脚本则不需要300秒运行完成只需要3秒即可,会自动在并发池中处理结果。
from function_scheduling_distributed_framework import PriorityConsumingControlConfig
from test_frame.test_rpc.test_consume import add
def show_result(status_and_result:dict):
"""
:param status_and_result: 一个字典包括了函数入参、函数结果、函数是否运行成功、函数运行异常类型
"""
print(status_and_result)
for i in range(100):
async_result = add.push(i, i * 2)
# print(async_result.result) # 执行 .result是获取函数的运行结果,会阻塞当前发布消息的线程直到函数运行完成。
async_result.set_callback(show_result) # 使用回调函数在线程池中并发的运行函数结果
4.7 演示qps控频
演示框架的qps控频功能
此框架对函数耗时随机波动很大的控频精确度达到96%以上
此框架对耗时恒定的函数控频精确度达到99.9%
在指定rate_limit 超过 20/s 时候,celery对耗时恒定的函数控频精确度60%左右,下面的代码会演示这两个框架的控频精准度对比。
此框架针对不同指定不同qps频次大小的时候做了不同的三种处理方式。 框架的控频是直接基于代码计数,而非使用redis 的incr计数,因为python操作一次redis指令要消耗800行代码左右, 如果所有任务都高频率incr很消耗python脚本的cpu也对redis服务端产生灾难压力。 例如假设有50个不同的函数,分别都要做好几千qps的控频,如果采用incr计数,光是incr指令每秒就要操作10万次redis, 所以如果用redis的incr计数控频就是个灾难,redis incr的计数只适合 1到10大小的qps,不适合 0.01 qps 和 1000 qps这样的任务。 同时此框架也能很方便的达到 5万 qps的目的,装饰器设置qps=50000 和 is_using_distributed_frequency_control=True, 然后只需要部署很多个进程 + 多台机器,框架通过redis统计活跃消费者数量,来自动调节每台机器的qps,框架的分布式控频开销非常十分低, 因为分布式控频使用的仍然不是redis的incr计数,而是基于每个消费者的心跳来统计活跃消费者数量,然后给每个进程分配qps的,依然基于本地代码计数。 例如部署100个进程(如果机器是128核的,一台机器足以,或者20台8核机器也可以) 以20台8核机器为例子,如果把机器减少到15台或增加机器到30台,随便减少部署的机器数量或者随便增加机器的数量, 代码都不需要做任何改动和重新部署,框架能够自动调节来保持持续5万次每秒来执行函数,不用担心部署多了30台机器,实际运行qps就变成了10几万。 (前提是不要把机器减少到10台以下,因为这里假设这个函数是一个稍微耗cpu耗时的函数,要保证所有资源硬件加起来有实力支撑5万次每秒执行函数) 每台机器都运行 test_fun.multi_process_conusme(8),只要10台以上1000台以下随意随时随地增大减小运行机器数量, 代码不需要做任何修改变化,就能很方便的达到每秒运行5万次函数的目的。
4.7.1 演示qps控频和自适应扩大和减小并发数量。
通过不同的时间观察控制台,可以发现无论f2这个函数需要耗时多久(无论是函数耗时需要远小于1秒还是远大于1秒),框架都能精确控制每秒刚好运行2次。
当函数耗时很小的时候,只需要很少的线程就能自动控制函数每秒运行2次。
当函数突然需要耗时很大的时候,智能线程池会自动启动更多的线程来达到每秒运行2次的目的。
当函数耗时从需要耗时很大变成只需要耗时很小的时候,智能线程池会自动缩小线程数量。
总之是围绕qps恒定,会自动变幻线程数量,做到既不多开浪费cpu切换,也不少开造成执行速度慢。
import time
import threading
from function_scheduling_distributed_framework import task_deco, BrokerEnum, ConcurrentModeEnum
t_start = time.time()
@task_deco('queue_test2_qps', qps=2, broker_kind=BrokerEnum.PERSISTQUEUE, concurrent_mode=ConcurrentModeEnum.THREADING, concurrent_num=600)
def f2(a, b):
"""
这个例子是测试函数耗时是动态变化的,这样就不可能通过提前设置参数预估函数固定耗时和搞鬼了。看看能不能实现qps稳定和线程池自动扩大自动缩小
要说明的是打印的线程数量也包含了框架启动时候几个其他的线程,所以数量不是刚好和所需的线程计算一样的。
"""
result = a + b
sleep_time = 0.01
if time.time() - t_start > 60: # 先测试函数耗时慢慢变大了,框架能不能按需自动增大线程数量
sleep_time = 7
if time.time() - t_start > 120:
sleep_time = 30
if time.time() - t_start > 240: # 最后把函数耗时又减小,看看框架能不能自动缩小线程数量。
sleep_time = 0.8
if time.time() - t_start > 300:
sleep_time = None
print(f'{time.strftime("%H:%M:%S")} ,当前线程数量是 {threading.active_count()}, {a} + {b} 的结果是 {result}, sleep {sleep_time} 秒')
if sleep_time is not None:
time.sleep(sleep_time) # 模拟做某事需要阻塞n秒种,必须用并发绕过此阻塞。
return result
if __name__ == '__main__':
f2.clear()
for i in range(1000):
f2.push(i, i * 2)
f2.consume()
4.7.2 此框架对固定耗时的任务,持续控频精确度高于99.9%
4.7.2 此框架对固定耗时的任务,持续控频精确度高于99.9%,远超celery的rate_limit 60%控频的精确度。
对于耗时恒定的函数,此框架精确控频率精确度达到99.9%,celery控频相当不准确,最多到达60%左右,两框架同样是做简单的加法然后sleep0.7秒,都设置500并发100qps。
@task_deco('test_queue66', broker_kind=BrokerEnum.REDIS, qps=100)
def f(x, y):
print(f''' {int(time.time())} 计算 {x} + {y} = {x + y}''')
time.sleep(0.7)
return x + y
@celery_app.task(name='求和啊', rate_limit='100/s')
def add(a, b):
print(f'{int(time.time())} 计算 {a} + {b} 得到的结果是 {a + b}')
time.sleep(0.7)
return a + b
# 在pycahrm控制台搜索 某一秒的时间戳 + 计算 作为关键字查询,分布式函数调度框架启动5秒后,以后持续每一秒都是100次,未出现过99和101的现象。
在pycahrm控制台搜索 某一秒的时间戳 + 计算 作为关键字查询,celery框架,每一秒求和次数都是飘忽不定的,而且是六十几徘徊,
如果celery能控制到95至105次每秒徘徊波动还能接受,类似现象还有celery设置rate_limit=50/s,实际32次每秒徘徊,
设置rate_limit=30/s,实际18-22次每秒徘徊,可见celery的控频相当差。
设置rate_limit=10/s,实际7-10次每秒徘徊,大部分时候是9次,当rate_limit大于20时候就越来越相差大了,可见celery的控频相当差。
4.7.3 对函数耗时随机性大的控频功能证明
对函数耗时随机性大的控频功能证明,使用外网连接远程broker,持续qps控频。
设置函数的qps为100,来调度需要消耗任意随机时长的函数,能够做到持续精确控频,频率误差小。
如果设置每秒精确运行超过500000次以上的固定频率,前提是cpu够强机器数量多,
设置qps=50000,并指定is_using_distributed_frequency_control=True(只有这样才是分布式全局控频,默认是基于单个进程的控频),。
如果任务不是很重型很耗cpu,此框架单个消费进程可以控制每秒运行次数的qps 从0.01到1000很容易。
当设置qps为0.01时候,指定的是每100秒运行1次,qps为100指的是每一秒运行100次。
import time
import random
from function_scheduling_distributed_framework import task_deco, BrokerEnum, run_consumer_with_multi_process
@task_deco('test_rabbit_queue7', broker_kind=BrokerEnum.RABBITMQ_AMQPSTORM, qps=100, log_level=20)
def test_fun(x):
# time.sleep(2.9)
# sleep时间随机从0.1毫秒到5秒任意徘徊。传统的恒定并发数量的线程池对未知的耗时任务,持续100次每秒的精确控频无能为力。
# 但此框架只要简单设置一个qps就自动达到了这个目的。
random_sleep = random.randrange(1, 50000) / 10000
time.sleep(random_sleep)
print(x, random_sleep)
if __name__ == '__main__':
test_fun.consume()
# test_fun.multi_process_consume(3)
分布式函数调度框架对耗时波动大的函数持续控频曲线
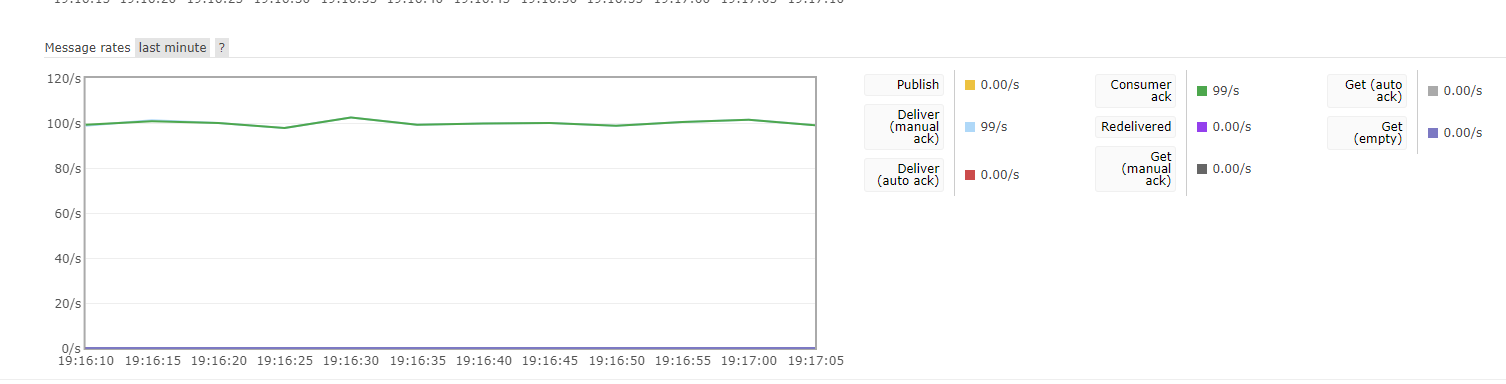 img_3.png
img_3.png
4.7.4 分布式全局控频和单个消费者控频区别
@task_deco中指定 is_using_distributed_frequency_control=True 则启用分布式全局控频,是跨进程跨python解释器跨服务器的全局控频。
否则是基于当前消费者的控频。
例如 你设置的qps是100,如果你不设置全局控频,run_consume.py 脚本中启动 fun.consume() ,如果你反复启动5次这个 run_consume.py,
如果不设置分布式控频,那么5个独立的脚本运行,频率总共会达到 500次每秒,因为你部署了5个脚本。
同理你如果用 fun.multi_process_consume(4)启动了4个进程消费,那么就是4个消费者,总qps也会达到400次每秒。
这个控频方式是看你需求了。
如果设置了 is_using_distributed_frequency_control=True,那就会使用每个消费者发送到redis的心跳来统计总消费者个数。
如果你部署了2次,那么每个消费者会平分qps,每个消费者是变成50qps,总共100qps。
如果你部署了5次,那么每个消费者会平分qps,每个消费者是变成20qps,总共100qps。
如果你中途关闭2个消费者,变成了3个消费者,每个消费者是变成 33.33qps,总共100qps。(框架qps支持小数,0.1qps表示每10秒执行1次)
4.8 再次说明qps能做什么,qps为什么流弊?常规并发方式无法完成的需求是什么?
以模拟请求一个flask接口为例子,我要求每一秒都持续精确完成8次请求,即控制台每1秒都持续得到8次flask接口返回的hello world结果。
4.8.1 下面讲讲常规并发手段为什么对8qps控频需求无能为力?
不用框架也可以实现8并发, 例如Threadpool设置8线程很容易,但不用框架实现8qps不仅难而且烦
虽然
框架能自动实现 单线程 ,多线程, gevent , eventlet ,asyncio ,多进程 并发 ,
多进程 + 单线程 ,多进程 + 多线程,多进程 + gevent, 多进程 + eventlet ,多进程 + asyncio 的组合并发
可以说囊括了python界的一切知名的并发模型,能做到这一点就很方便强大了
但是
此框架还额外能实现qps控频,能够实现函数每秒运行次数的精确控制,我觉得这个功能也很实用,甚至比上面的那些并发用起来还实用。
这个代码是模拟常规并发手段无法达到每秒持续精确运行8次函数(请求flask接口8次)的目的。
下面的代码使用8个线程并发运行 request_flask_api 函数,
当flask_veiw_mock 接口耗时0.1秒时候,在python输出控制台可以看到,10秒钟就运行结束了,控制台每秒打印了80次hello world,严重超频10倍了不符合需求
当flask_veiw_mock 接口耗时刚好精确等于1秒时候,在python输出控制台可以看到,100秒钟运行结束了,控制台每秒打印了8次hello world,只有当接口耗时刚好精确等于1秒时候,并发数量才符合qps需求
当flask_veiw_mock 接口耗时10秒时候,在python输出控制台可以看到,需要1000秒钟运行结束,控制台每隔10秒打印8次hello world,严重不符合持续每秒打印8次的目的。
由此可见,用设置并发数量来达到每秒请求8次flask的目的非常困难,99.99%的情况下服务端没那么巧刚好耗时1秒。
天真的人会说根据函数耗时大小,来设置并发数量,这可行吗?
有人会说,为了达到8qps目的,当函数里面sleep 0.1 时候他开1线程,那你这样仍然超频啊,你是每1秒钟打印10次了超过了8次。
当sleep 0.01 时候,为了达到8qps目的,就算你开1线程,那不是每1秒钟打印100次hello?你不会想到开0.08个线程个线程来实现控频吧?
当sleep 10秒时候,为了8qps目的,你开80线程,那这样是控制台每隔10秒打印80次hello,我要求的是控制台每一秒都打印8次hello,没告诉你是每隔10秒打印80次hello吧?还是没达到目的。
如果函数里面是sleep 0.005 0.07 0.09 1.3 2.7 7 11 13这些不规则无法整除的数字?请问你是如何一一计算精确开多少线程来达到8qps的?
如果flask网站接口昨天是3秒的响应时间,今天变成了0.1秒的响应时间,你的线程池数量不做变化,代码不进行重启,请问你如何做到自适应无视请求耗时,一直持续8qps的目的?
固定并发数量大小就是定速巡航不够智能前车减速会撞车,qps自适应控频那就是acc自适应巡航了,自动调整极端智能,压根无需提前测算预估函数需要耗时多久(接口响应耗时多久)。
所以综上所述,如果你有控频需求,你想用并发数量来达到控频目的,那是不可能的。
有些人到现在还没明白并发数量和qps(每秒执行多少次)之间的区别,并发数量只有在函数耗时刚好精确等于1秒时候才等于qps。
```python
import time
from concurrent.futures import ThreadPoolExecutor
def flask_veiw_mock(x):
# time.sleep(0.1) # 通过不同的sleep大小来模拟服务端响应需要消耗的时间
# time.sleep(1) # 通过不同的sleep大小来模拟服务端响应需要消耗的时间
time.sleep(10) # 通过不同的sleep大小来模拟服务端响应需要消耗的时间
return f"hello world {x}"
def request_flask_api(x):
response = flask_veiw_mock(x)
print(time.strftime("%H:%M:%S"), ' ', response)
if __name__ == '__main__':
with ThreadPoolExecutor(8) as pool:
for i in range(800):
pool.submit(request_flask_api,i)
截图是当 flask_veiw_mock 耗时为10秒时候,控制台是每隔10秒打印8次 hello world,没达到每一秒都打印8次的目的
当 flask_veiw_mock 耗时为0.1 秒时候,控制台是每隔1秒打印80次 hello world,没达到每一秒都打印8次的目的
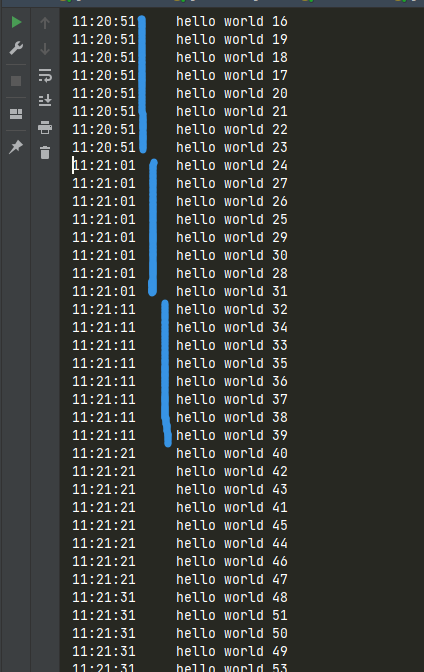 img_16.png
img_16.png
4.8.2 使用分布式函数调度框架,无论接口耗时多少,轻松达到8qps的例子
这个代码是模拟常规并发手段无法达到每秒持续精确运行8次函数(请求flask接口8次)的目的。
但是使用分布式函数调度框架能轻松达到这个目的。
下面的代码使用分部署函数调度框架来调度运行 request_flask_api 函数,
flask_veiw_mock 接口耗时0.1秒时候,控制台每秒打印8次 hello world,非常精确的符合控频目标
flask_veiw_mock 接口耗时1秒时候,控制台每秒打印8次 hello world,非常精确的符合控频目标
flask_veiw_mock 接口耗时10秒时候控,控制台每秒打印8次 hello world,非常精确的符合控频目标
flask_veiw_mock 接口耗时0.001秒时候,控制台每秒打印8次 hello world,非常精确的符合控频目标
flask_veiw_mock 接口耗时50 秒时候,控制台每秒打印8次 hello world,非常精确的符合控频目标
可以发现分布式函数调度框架无视函数耗时大小,都能做到精确控频,常规的线程池 asyncio什么的,面对这种不确定的接口耗时,简直毫无办法。
有些人到现在还没明白并发数量和qps(每秒执行多少次)之间的区别,并发数量只有在函数耗时刚好精确等于1秒时候才等于qps。
import time
from function_scheduling_distributed_framework import task_deco,BrokerEnum
def flask_veiw_mock(x):
time.sleep(0.1) # 通过不同的sleep大小来模拟服务端响应需要消耗的时间
# time.sleep(1) # 通过不同的sleep大小来模拟服务端响应需要消耗的时间
# time.sleep(10) # 通过不同的sleep大小来模拟服务端响应需要消耗的时间
return f"hello world {x}"
@task_deco("test_qps",broker_kind=BrokerEnum.MEMORY_QUEUE,qps=8)
def request_flask_api(x):
response = flask_veiw_mock(x)
print(time.strftime("%H:%M:%S"), ' ', response)
if __name__ == '__main__':
for i in range(800):
request_flask_api.push(i)
request_flask_api.consume()
从截图可以看出,分布式函数调度框架,控频稳如狗,完全无视flask_veiw_mock耗时是多少。
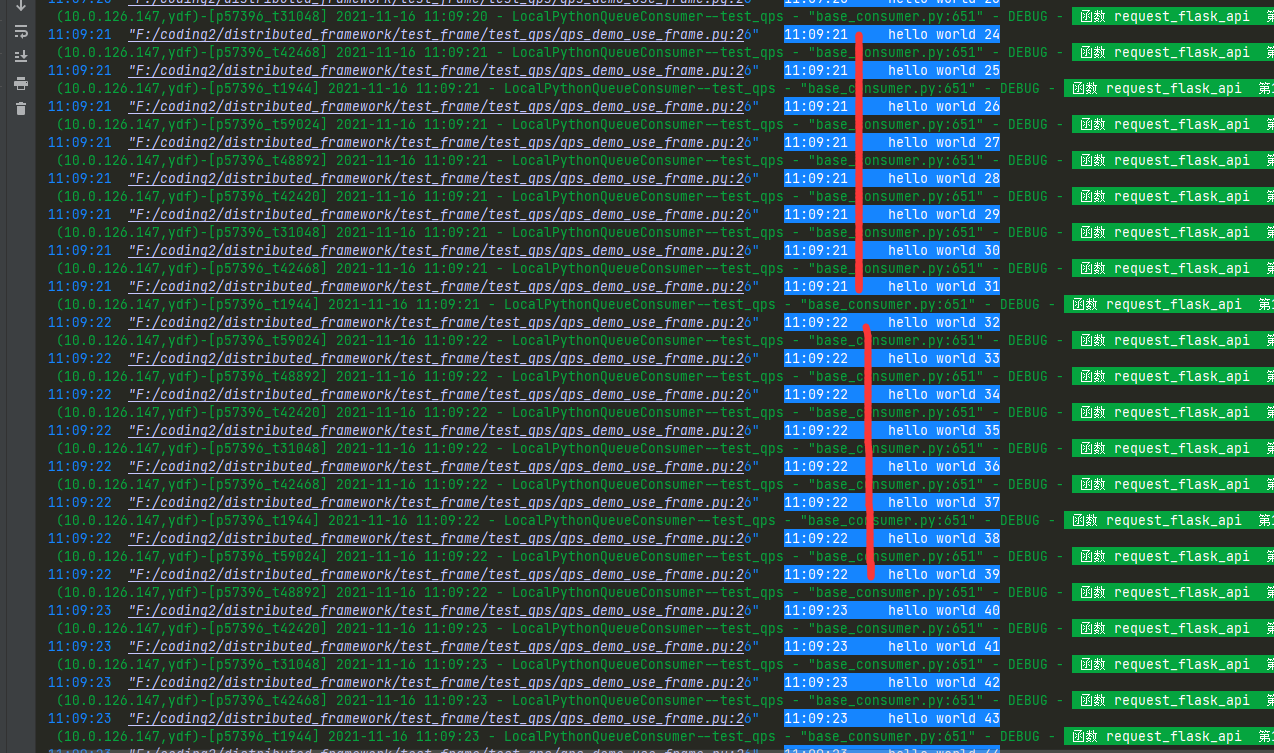 img_17.png
img_17.png
有些人到现在还没明白并发数量和qps(每秒执行多少次)之间的区别,并发数量只有在函数耗时刚好精确等于1秒时候才等于qps。
4.9 演示延时运行任务
因为有很多人有这样的需求,希望发布后不是马上运行,而是延迟60秒或者现在发布晚上18点运行。
然来是希望用户自己亲自在消费函数内部写个sleep(60)秒再执行业务逻辑,来达到延时执行的目的,
但这样会被sleep占据大量的并发线程/协程,如果是用户消费函数内部写sleep7200秒这么长的时间,那
sleep等待会占据99.9%的并发工作线程/协程的时间,导致真正的执行函数的速度大幅度下降,所以框架
现在从框架层面新增这个延时任务的功能。
之前已做的功能是定时任务,现在新增延时任务,这两个概念有一些不同。
定时任务一般情况下是配置为周期重复性任务,延时任务是一次性任务。
1)框架实现定时任务原理是代码本身自动定时发布,自然而然就能达到定时消费的目的。
2)框架实现延时任务的原理是马上立即发布,当消费者取出消息后,并不是立刻去运行,
而是使用定时运行一次的方式延迟这个任务的运行。
在需求开发过程中,我们经常会遇到一些类似下面的场景:
1)外卖订单超过15分钟未支付,自动取消
2)使用抢票软件订到车票后,1小时内未支付,自动取消
3)待处理申请超时1天,通知审核人员经理,超时2天通知审核人员总监
4)客户预定自如房子后,24小时内未支付,房源自动释放
分布式函数调度框架的延时任务概念类似celery的countdown和eta入参, add.apply_async(args=(1, 2),countdown=20) # 规定取出后20秒再运行
此框架的入参名称那就也叫 countdown和eta。
countdown 传一个数字,表示多少秒后运行。
eta传一个datetime对象表示,精确的运行时间运行一次。
消费,消费代码没有任何变化
from function_scheduling_distributed_framework import task_deco, BrokerEnum
@task_deco('test_delay', broker_kind=BrokerEnum.REDIS_ACK_ABLE)
def f(x):
print(x)
if __name__ == '__main__':
f.consume()
发布延时任务
# 需要用publish,而不是push,这个前面已经说明了,如果要传函数入参本身以外的参数到中间件,需要用publish。
# 不然框架分不清哪些是函数入参,哪些是控制参数。如果无法理解就,就好好想想琢磨下celery的 apply_async 和 delay的关系。
from test_frame.test_delay_task.test_delay_consume import f
import datetime
import time
from function_scheduling_distributed_framework import PriorityConsumingControlConfig
"""
测试发布延时任务,不是发布后马上就执行函数。
countdown 和 eta 只能设置一个。
countdown 指的是 离发布多少秒后执行,
eta是指定的精确时间运行一次。
misfire_grace_time 是指定消息轮到被消费时候,如果已经超过了应该运行的时间多少秒之内,仍然执行。
misfire_grace_time 如果设置为None,则消息一定会被运行,不会由于大连消息积压导致消费时候已近太晚了而取消运行。
misfire_grace_time 如果不为None,必须是大于等于1的整数,此值表示消息轮到消费时候超过本应该运行的时间的多少秒内仍然执行。
此值的数字设置越小,如果由于消费慢的原因,就有越大概率导致消息被丢弃不运行。如果此值设置为1亿,则几乎不会导致放弃运行(1亿的作用接近于None了)
如果还是不懂这个值的作用,可以百度 apscheduler 包的 misfire_grace_time 概念
"""
for i in range(1, 20):
time.sleep(1)
# 消息发布10秒后再执行。如果消费慢导致任务积压,misfire_grace_time为None,即使轮到消息消费时候离发布超过10秒了仍然执行。
f.publish({'x': i}, priority_control_config=PriorityConsumingControlConfig(countdown=10))
# 规定消息在17点56分30秒运行,如果消费慢导致任务积压,misfire_grace_time为None,即使轮到消息消费时候已经过了17点56分30秒仍然执行。
f.publish({'x': i * 10}, priority_control_config=PriorityConsumingControlConfig(
eta=datetime.datetime(2021, 5, 19, 17, 56, 30) + datetime.timedelta(seconds=i)))
# 消息发布10秒后再执行。如果消费慢导致任务积压,misfire_grace_time为30,如果轮到消息消费时候离发布超过40 (10+30) 秒了则放弃执行,
# 如果轮到消息消费时候离发布时间是20秒,由于 20 < (10 + 30),则仍然执行
f.publish({'x': i * 100}, priority_control_config=PriorityConsumingControlConfig(
countdown=10, misfire_grace_time=30))
# 规定消息在17点56分30秒运行,如果消费慢导致任务积压,如果轮到消息消费时候已经过了17点57分00秒,
# misfire_grace_time为30,如果轮到消息消费时候超过了17点57分0秒 则放弃执行,
# 如果如果轮到消息消费时候是17点56分50秒则执行。
f.publish({'x': i * 1000}, priority_control_config=PriorityConsumingControlConfig(
eta=datetime.datetime(2021, 5, 19, 17, 56, 30) + datetime.timedelta(seconds=i),
misfire_grace_time=30))
# 这个设置了消息由于推挤导致运行的时候比本应该运行的时间如果小于1亿秒,就仍然会被执行,所以几乎肯定不会被放弃运行
f.publish({'x': i * 10000}, priority_control_config=PriorityConsumingControlConfig(
eta=datetime.datetime(2021, 5, 19, 17, 56, 30) + datetime.timedelta(seconds=i),
misfire_grace_time=100000000))
4.10 在web中如flask fastapi django 如何搭配使用消费框架的例子。
在web中推送任务,后台进程消费任务,很多人问怎么在web使用,用法和不与web框架搭配并没有什么不同之处。
因为发布和消费是使用中间件解耦的,一般可以分成web接口启动一次,后台消费启动一次,需要独立部署两次。
演示了flask 使用app应用上下文。
web接口中发布任务到消息队列,独立启动异步消费。
flask + 分布式函数调度框架演示例子在:
https://github.com/ydf0509/distributed_framework/blob/master/test_frame/use_in_flask_tonardo_fastapi
fastapi + 分布式函数调度框架演示例子在: https://github.com/ydf0509/fastapi_use_distributed_framework_demo
如果前端在乎任务的结果:
非常适合使用mqtt, 前端订阅唯一uuid的topic 然后表单中带上这个topic名字请求python接口 -> 接口中发布任务到rabbitmq或redis消息队列 ->
后台消费进程执行任务消费,并将结果发布到mqtt的那个唯一uuid的topic -> mqtt 把结果推送到前端。
使用ajax轮训或者后台导入websocket相关的包来做和前端的长耗时任务的交互 是伪命题。
4.11 开启消费状态、结果web页面
(1)需要安装mongodb,并且设置 MONGO_URL 的值
如果需要使用这个页面,那么无论选择何种中间件,即使不是使用mongo作为消息队列,也需要安装mongodb,因为因为是从这里读取数据的。
需要在 distributed_frame_config.py 中设置MONGO_URL的值,mongo url的格式如下,这是通用的可以百度mongo url连接形式。
有密码 MONGO_CONNECT_URL = f'mongodb://yourname:yourpassword@127.0.01:27017/admin'
没密码 MONGO_CONNECT_URL = f'mongodb://192.168.6.132:27017/'
(2) 装饰器上需要设置持久化的配置参数,代码例子
框架默认不会保存消息状态和结果到mongo的,因为大部分人并没有安装mongo,且这个web显示并不是框架代码运行的必须部分,还有会降低一丝丝运行性能。
框架插入mongo的原理是采用先进的自动批量聚合插入,例如1秒运行几千次函数,并不会操作几千次mongo,是2秒操作一次mongo
如果需要页面显示消费状态和结果,需要配置装饰器的 function_result_status_persistance_conf 的参数
FunctionResultStatusPersistanceConfig的如参是 (is_save_status: bool, is_save_result: bool, expire_seconds: int)
is_save_status 指的是是否保存消费状态,这个只有设置为True,才会保存消费状态到mongodb,从而使web页面能显示该队列任务的消费信息
is_save_result 指的是是否保存消费结果,如果函数的结果超大字符串或者对函数结果不关心或者函数没有返回值,可以设置为False。
expire_seconds 指的是多久以后,这些保存的数据自动从mongodb里面消失删除,避免爆磁盘。
from function_scheduling_distributed_framework import task_deco, FunctionResultStatusPersistanceConfig
@task_deco('queue_test_f01', qps=2,function_result_status_persistance_conf=FunctionResultStatusPersistanceConfig(True, True, 7 * 24 * 3600))
def f(a, b):
return a + b
f(5, 6) # 可以直接调用
for i in range(0, 200):
f.push(i, b=i * 2)
f.consume()
(3)启动python分布式函数调度框架之函数运行结果状态web
web代码在function_scheduling_distributed_framework包里面,所以可以直接使用命令行运行起来,不需要用户现亲自下载代码就可以直接运行。
# 第一步 export PYTHONPATH=你的项目根目录 ,这么做是为了这个web可以读取到你项目根目录下的distributed_frame_config.py里面的配置
# 例如 export PYTHONPATH=/home/ydf/codes/ydfhome
或者 export PYTHONPATH=./ (./是相对路径,前提是已近cd到你的项目根目录了)
第二步
win上这么做 python3 -m function_scheduling_distributed_framework.function_result_web.app
linux上可以这么做使用gunicorn启动性能好一些,当然也可以按win的做。
gunicorn -w 4 --threads=30 --bind 0.0.0.0:27018 function_scheduling_distributed_framework.function_result_web.app:app
(4)使用浏览器打开 127.0.0.1(启动web服务的机器ip):27018,输入默认用户名 密码 admin 123456,即可打开函数运行状态和结果页面。
4.12 框架 asyncio 方式运行协程
见7.8的demo介绍,
@task_deco(….,concurrent_mode=ConcurrentModeEnum.ASYNC)
这种方式是@task_deco装饰在async def定义的函数上面。
celery不支持直接调度执行async def定义的函数,但此框架是直接支持asyncio并发的。
4.13 跨python项目怎么发布任务或者获取函数执行结果?
别的语言项目或者别的python项目手动发布消息到中间件,让分布式函数调度框架消费任务,
例如项目b中有add函数,项目a里面无法 import 导入这个add 函数。
1)第一种方式,使用能操作消息中间件的python包,手动发布任务到消息队列中间件
如果是别的语言发布任务,或者python项目a发布任务但是让python项目b的函数去执行,可以直接发布消息到中间件里面。
手动发布时候需要注意 中间件类型 中间件地址 队列名 @task_deco和distributed_frame_config.py指定的配置要保持一致。
需要发布的消息内容是 入参字典转成json字符串,然后发布到消息队列中间件。
以下以redis中间件为例子。演示手动发布任务到中间件。
@task_deco('test_queue668', broker_kind=BrokerEnum.REDIS)
def add(x, y):
print(f''' 计算 {x} + {y} = {x + y}''')
time.sleep(4)
return x + y
if __name__ == '__main__':
r = Redis(db=7,host='127.0.0.1')
for i in range(10):
add.push(i, i * 2) # 正常同一个python项目是这么发布消息,使用函数.push或者publish方法
r.lpush('test_queue668',json.dumps({'x':i,'y':i*2})) # 不同的项目交互,可以直接手动发布消息到中间件
这个很容易黑盒测试出来,自己观察下中间件里面的内容格式就能很容易手动模仿构造出消息内容了。
需要说明的是 消息内容不仅包括 入参本身,也包括其他控制功能的辅助参数,可以用框架的自动发布功能发布消息,然后观察中间件里面的字段内容,模拟构造。
举个例子之一,例如如果要使用消息过期丢弃这个功能,那么就需要发布消息当时的时间戳了。
第二种方式,使用伪函数来作为任务,只写函数声明不写函数体。
此方式是一名网友的很机智的建议,我觉得可行。
例如还是以上面的求和函数任务为例,在项目a里面可以定义一个假函数声明,并且将b项目的求和add函数装饰器复制过去,但函数体不需要具体内容
@task_deco('test_queue668', broker_kind=BrokerEnum.REDIS) # a项目里面的这行和b项目里面的add函数装饰器保持一致。
def add(x, y): # 方法名可以一样,也可以不一样,但函数入参个数 位置 名称需要保持不变。
pass # 方法体,没有具体的求和逻辑代码,只需要写个pass就行了。
之后通过这个假的add函数就可以享受到与在同一个项目中如何正常发布和获取求和函数的执行结果 一模一样的写法方式了。
例如add.clear() 清空消息队列,add.push发布,add.publish发布,async_result.get获取结果,都可以正常使用,
但不要使用add.consume启动消费,因为这个是假的函数体,不能真正的执行求和.
4.14 [分布式函数调度框架qq群]
现在新建一个qq群 189603256